Recent text-to-video generation approaches rely on computationally heavy training and require large-scale video datasets. In this paper, we introduce a new task of zero-shot text-to-video generation and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g. Stable Diffusion), making them suitable for the video domain. Our key modifications include (i) enriching the latent codes of the generated frames with motion dynamics to keep the global scene and the background time consistent; and (ii) reprogramming frame-level self-attention using a new cross-frame attention of each frame on the first frame, to preserve the context, appearance, and identity of the foreground object. Experiments show that this leads to low overhead, yet high-quality and remarkably consistent video generation. Moreover, our approach is not limited to text-to-video synthesis but is also applicable to other tasks such as conditional and content-specialized video generation, and Video Instruct-Pix2Pix, i.e., instruction-guided video editing. As experiments show, our method performs comparably or sometimes better than recent approaches, despite not being trained on additional video data. Our code will be open sourced at: https://github.com/Picsart-AI-Research/Text2Video-Zero.
Method overview: Starting from a randomly sampled latent code \(x_{T}^{1}\), we apply \(\Delta t\) DDIM backward steps to obtain \(x_{T'}^{1}\) using a pre-trained Stable Diffusion model (SD). A specified motion field results for each frame \(k\) in a warping function \(W_k\) that turns \(x_{T'}^{1}\) to \(x_{T'}^{k}\). By enhancing the latent codes with motion dynamics, we determine the global scene and camera motion and achieve temporal consistency in the background and the global scene. A subsequent DDPM forward application delivers latent codes \(x_{T}^{k}\) for \(k=1,\ldots,m\). By using the (probabilistic) DDPM method, a greater degree of freedom is achieved with respect to the motion of objects. Finally, the latent codes are passed to our modified SD model using the proposed cross-frame attention, which uses keys and values from the first frame to generate the image of frame \(k=1,\ldots,m\). By using cross-frame attention, the appearance and the identity of the foreground object are preserved throughout the sequence. Optionally, we apply background smoothing. To this end, we employ salient object detection to obtain for each frame \(k\) a mask \(M^{k}\) indicating the foreground pixels. Finally, for the background (using the mask \(M^{k}\)), a convex combination between the latent code \(x_{t}^{1}\) of frame one warped to frame \(k\) and the latent code \(x_{t}^{k}\) is used to further improve the temporal consistency of the background.
 |
 |
 |
 |
| "A cat is running on the grass" | "A panda is playing guitar on times square | "A man is running in the snow" | "An astronaut is skiing down the hill" |
 |
 |
 |
 |
| "A panda surfing on a wakeboard" | "A bear dancing on times square | "A man is riding a bicycle in the sunshine" | "A horse galloping on a street" |
 |
 |
 |
 |
| "A tiger walking alone down the street" | "A panda surfing on a wakeboard | "A horse galloping on a street" | "A cute cat running in a beatiful meadow" |
 |
 |
 |
 |
| "A horse galloping on a street" | "A panda walking alone down the street | "A dog is walking down the street" | "An astronaut is waving his hands on the moon" |
  |
  |
  |
  |
| "A bear dancing on the concrete" | "An alien dancing under a flying saucer | "A panda dancing in Antarctica" | "An astronaut dancing in the outer space" |
  |
  |
  |
  |
| "White butterfly" | "Beautiful girl" | "A jellyfish" | "beautiful girl halloween style" |
  |
  |
  |
 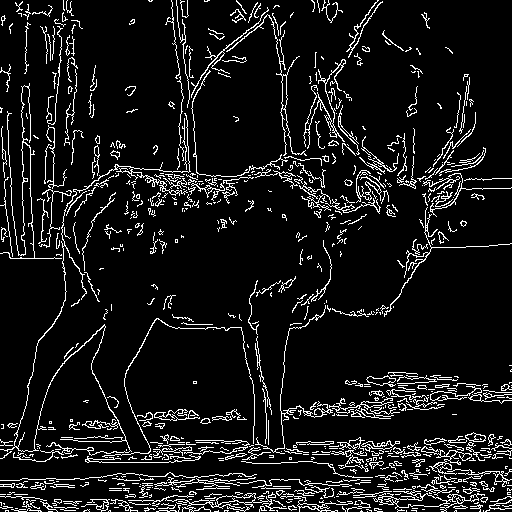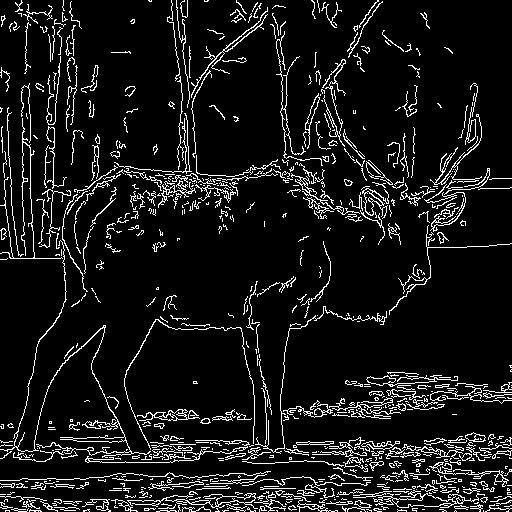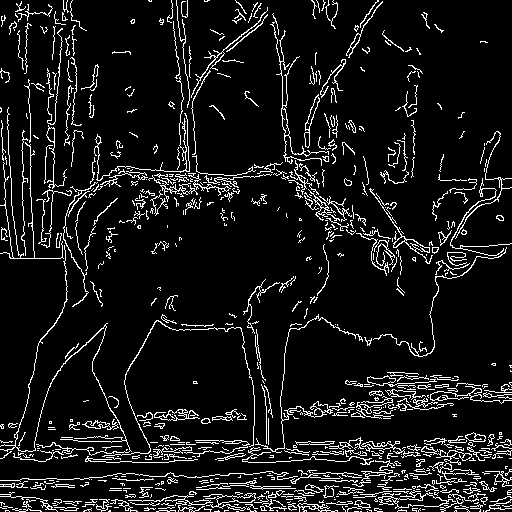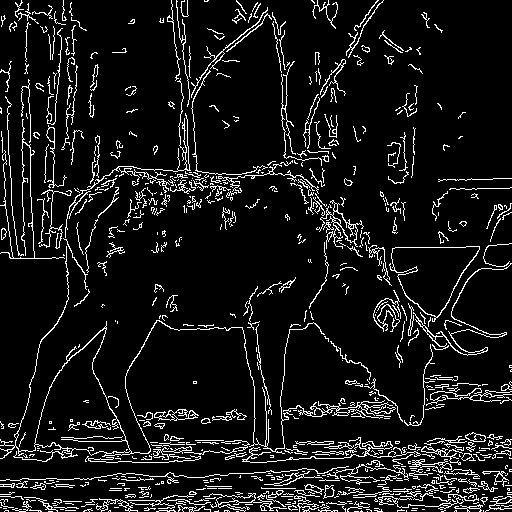 |
| "Wild fox is walking" | "Oil painting of a beautiful girl close-up" | "A santa claus" | "A deer" |
  |
  |
  |
  |
| "anime style" | "arcane style | "gta-5 man" | "avatar style" |
  |
  |
  |
| "Replace man with chimpanze" | "Make it Van Gogh Starry Night style" | "Make it Picasso style" |
  |
  |
  |
| "Make it Expressionism style" | "Make it night" | "Make it autumn" |
If you use our work in your research, please cite our publication:
@article{text2video-zero,
title={Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators},
author={Khachatryan, Levon and Movsisyan, Andranik and Tadevosyan, Vahram and Henschel, Roberto and Wang, Zhangyang and Navasardyan, Shant and Shi, Humphrey},
journal={arXiv preprint arXiv:2303.13439},
year={2023}
}

